
As the Fourth Industrial Revolution evolves and our society and its organizations continue transitioning to what some call the “Age of Data”, certain things have become undeniably self-evident.
For one, the amount and velocity of data companies face is now far greater than ever before.
Organizations must also handle more and more novel data types, including IoT, clickstream and streaming data, that their legacy systems cannot always handle.
To complicate matters even further, their employees and partners are now accustomed to accessing internal data from anywhere, on any device, along with having the ability to create data anywhere on their device.
Put simply, data is quickly moving beyond traditional organizational boundaries. This is something companies were, quite frankly, already struggling with earlier. But then COVID-19 came along and upended everything.
How COVID-19 crystallized the need for data identification
When COVID-19 appeared pretty much everyone who could do so was sent home to work remotely – and rightfully so.
But for many organizations this transition wasn’t easy. Along with the need to configure systems so employees could access the apps and data they need from anywhere, companies very quickly became concerned about how (and where) their data was being used.
The main issue? Most organizations didn’t (and many still don’t) have good visibility into their data.
That means they often have a hard time understanding where critical and sensitive information lives, how it is accessed each day, and how it is consumed by end users and their various devices.
This problem is compounded significantly for organizations post COVID-19 as:
- employees working remotely and often using their own devices to access, share and create information;
- attack surface for hackers increasing as users are now working on less secure environment and devices; and
- increased attacks targeting data and end users.
It’s imperative now for organizations to treat data as their new perimeter and have as many controls around data to establish efficient data protection frameworks and for these controls to be effective it’s important to establish persistent identity to information assets.
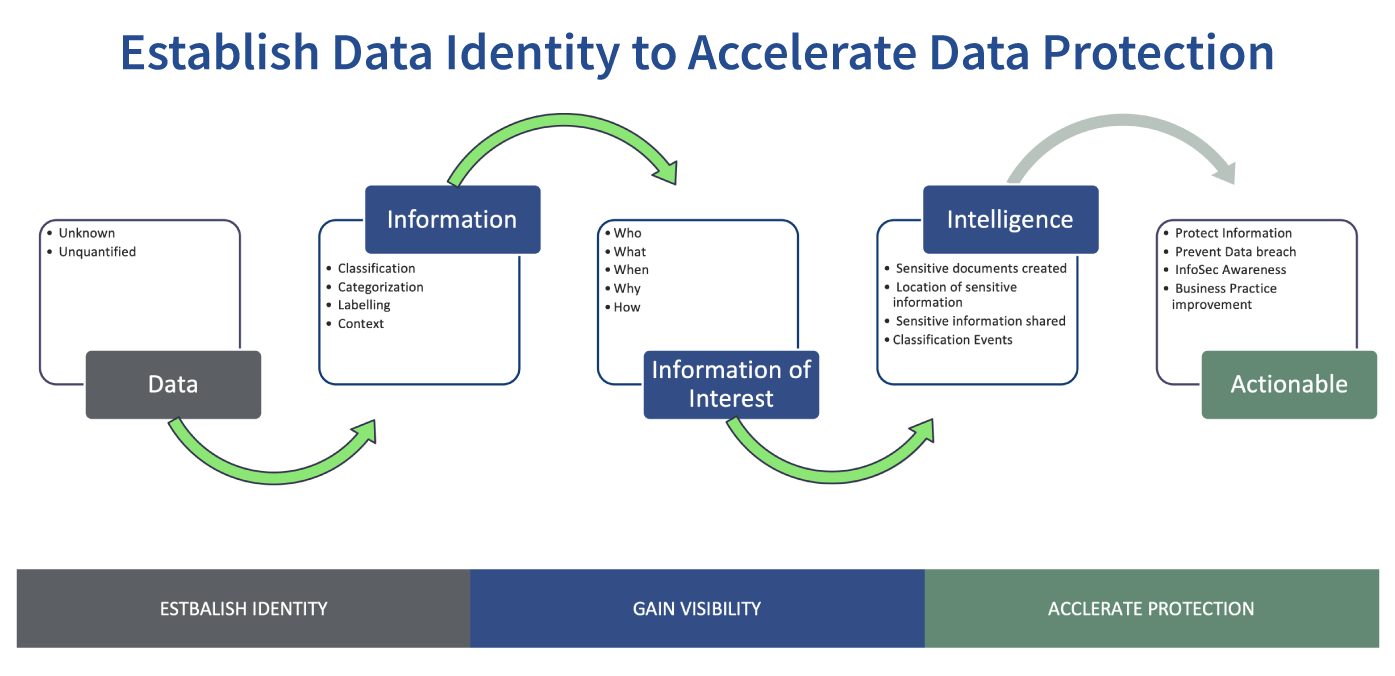
The figure below illustrates how establishing identity to data translates unknown/unquantified data into meaningful information.
This helps organizations gain extensive visibility to specific information of interest (Regulatory Data, Intellectual Property, Sensitive corporate data etc.), thereby providing organizations the much needed intelligence (where is the data residing, which business processes/departments are using the information, and how is the information shared internally/externally etc.).
This can then be used to accelerate protection by leveraging data protection controls (DLP, IRM, CASB, NGFW, Secure Email/Web Gateway etc.) deployed already at various layers within the organization.
The importance of establishing effective data identification
Organizations who want to stay compliant, avoid data breaches, and protect their data must be able to quickly identify and classify their critical information assets or crown jewels across the enterprise.
Embedding data identity through simple classification, tagging, or labelling might not help organizations in protecting information effectively.
For instance, classifying information across the enterprise into broad categories (Restricted, Confidential, Internal, Public) will not provide enough context like to which department the information belongs, whether it has regulatory information or not etc. and hence not helping organizations in identifying and protecting critical information assets comprehensively.
A solution should provide enough context persistently to answer a few important questions:
- What category of document is it? (Financial, Legal, IP, regulatory data etc.)
- What department owns the document?
- How sensitive is the document?
- How should it be handled? (Encrypted, enforced retention dates, quarantined to a secure data store etc.)
This can be achieved by leveraging Machine Learning, Natural Language Processing, Smart Regex, and also analyzing document/email attributes, and document structures.
The diagram below indicates how Fortra’s Data Classification Suite can extract a wide range of information embedded in a mortgage loan agreement.
An analysis of the high-lighted sections can help determine the document category, PII Type, how long it should be retained, the loan ID, whether it should be encrypted, and more.
Fortra’s Data Classification Suite captures and stores this information in persistent metadata, which can be consumed by various data protection/management controls (DLP, CASB, IRM, NGFW, Secure Email/Web Gateway, Archival etc.) to automate data security controls.
How do downstream technologies leverage Fortra’s Data Classification Suite metadata?
- CASB can read document metadata and ensure restricted/internal documents are not shared to external users or unmanaged assets.
- DLP can read metadata from email and ensure restricted/internal emails are not shared with external recipients.
- Archival tools can delete document once retention date set by Fortra’s Data Classification Suite expires from all archived locations.
In that sense, data identification can act as an orchestration layer to automate data security controls, thereby significantly reducing operational overheads and helping organizations to extract maximum ROI on data security investments.
Fortra’s Data Classification Suite also improves data security programs by proactively engaging users and educating them on data loss risks, establishing a culture where users are held accountable to determine information sensitivity.
The growth of Fortra’s Data Classification Suite in India, a hotbed of data protection
Fortra’s Data Classification Suite India established its operations in India a little more than two years ago.
Since then we’ve built incredible momentum across the subcontinent by assembling an ecosystem with a dozen strategic partners, along with a client roster of nearly 30 companies.
We also have established a full-fledged technical support and professional service team based out of Chennai to provide best-of-breed support to our customers and partners.
From the outset, our goal was to establish ourselves as a strong data identification brand in India by helping customers to embrace effective data governance through the Fortra’s Data Classification Suite solution offerings.
This was made partially easier thanks to India’s red-hot data protection market.
Indian companies already do a lot of work for clients in jurisdictions with stringent data protection laws (e.g., GDPR in Europe), industry regulatory guidelines (e.g., RBI, IRDA, TRAI), which necessitates strong data protection.
The country’s evolving draft data protection law has also been a factor.
Analysts and various consultants recommending customers who have deployed data protection controls to also deploy data classification and identification tools has been a major driver for customers to invest in data identification solutions.
Fortra’s Data Classification Suite at industry events
I was recently invited to a series of events held by the Confederation of Indian Industry (CII), iValue, and the India Chapter of the Information Security Forum (ISF), to discuss how to establish effective data protection.
The overall theme of these events was around data protection and how organizations must evolve data security frameworks to overcome the challenges, especially in a world still dealing with COVID-19 disruptions.
Data Security is a journey and revolves around people, process, and technology controls.
Intelligent data identification forms the foundational layer for enforcing efficient data security and most delegates at these events agreed they have gaps in their data security posture.
As a result, Fortra’s Data Classification Suite is planning a series of online workshops on how to review existing data protection ecosystems.
In my experience, successful data protection solutions share common characteristics;
- They’re flexible enough to seamlessly fit into an organization’s culture;
- They engage users and cause minimal-to-no user friction; and
- They clearly demonstrate the benefits they bring to both end users and CISOs/CDOs/CTOs with the company
Hence, I would recommend organizations check how the technology they consider for enforcing data identification strategies aligns with their organization’s culture, how it adapts to diverse requirements with various business functions, and how significantly it reduces the efforts it takes to be a key decision-maker.

