A corporate data security policy that sets out how valuable information should be handled will be ineffective unless it’s consistently and accurately enforced. Organizations often have a written policy that’s available on their company intranet and handed to new starters. In practice, however, employees are rarely sure how to apply it to their daily activities.
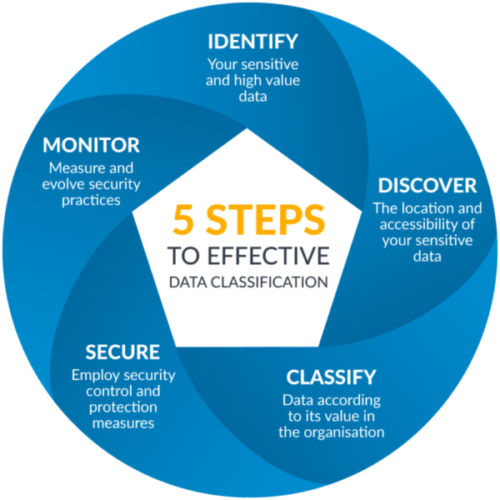
The security policy needs to be made actionable – and the best way of doing this is with the classification of data. This is the first of the two steps that involve actively securing data, with the second being the implementation of technology solutions that will protect it downstream. Classification makes those solutions more effective.
Data classification is the categorization of data according to its level of sensitivity or value, using labels. These are attached as visual markings, and also embedded into the metadata of the file. When classification is applied in association with downstream security solutions, the metadata ensures that the data can only be accessed or used in accordance with the rules that correspond with its label.
It’s possible to completely automate the process, but our clients get the best results when they combine human input with the use of software toolsets to support successful implementation. This is known as user-driven data classification.
With this approach the employee is responsible for deciding which label is appropriate, and attaching it at the point of creating, editing, sending or saving. The user’s insight into the context around the data leads to more accurate classification decisions than a computer could ever make.
Defining the classification policy
First, be clear on who should have access to each type of data. Next, decide how many categories you’ll have. Aim for three or four – the fewer the options the simpler it is for users. Labels that indicate Confidential, Internal only and Public are a good start, with perhaps a fourth category relating to information that’s subject to regulatory controls – such as GDPR, ITAR controlled or HIPAA/HITECH restricted.
Selecting your classification tool
The right technology will help your users to consistently apply the classification scheme, and will also add the all-important metadata. The most effective tools make classification a seamless part of business-as-usual; integrating the labelling process into the standard applications employees already use. Ensuring breadth of coverage across operating systems and application types is vital to future-proof your investment.
See recent reviews on Fortra's Classifier Suite here.
Rolling out data classification in your organization
Start by classifying your ‘live’ data – the emails, files and documents that are being created and handled right now. If you’ve followed steps 1 and 2 you’ll know exactly what and where it is. By doing this, you’re ensuring that all your ‘crown jewels’ will be safely locked up from this point forward. When that is established decide how to label the existing and legacy data that is stored and held around the organization. This process usually works well in combination with a discovery agent or tool.
Once you’ve labelled your data, it’s time to turn your attention to the enterprise security solutions and information management technologies that will control and protect it throughout the remainder of its journey.
Download The 5 Steps To Effective Data Protection
This will guide you through the 5 steps to implementing effective data protection within your organization, and detail how data classification can also enhance previously implemented tools, such as data loss prevention tools (DLP), data discovery tools, data governance tools and more.

